CUDA 学习笔记(二):编译流程与 PTX 架构
CUDA 学习笔记(二):编译流程与 PTX 架构
NVCC 编译流程
CUDA 程序使用 nvcc 编译器进行编译,从 .cu 源文件到可执行文件经历多个阶段:
1
2
3
4
5
6
7
8
9
# 一步到位编译
nvcc hello.cu -o hello
# 分步编译
nvcc -E hello.cu -o hello.i # 预处理
nvcc -ptx hello.i -o hello.ptx # 编译为 PTX
nvcc -c hello.ptx -o hello.cubin # 编译为 SASS(二进制)
nvcc -dlink hello.cubin -o hello_dlink.o # 设备链接
nvcc hello_dlink.o -o hello # 主机链接
编译流程图
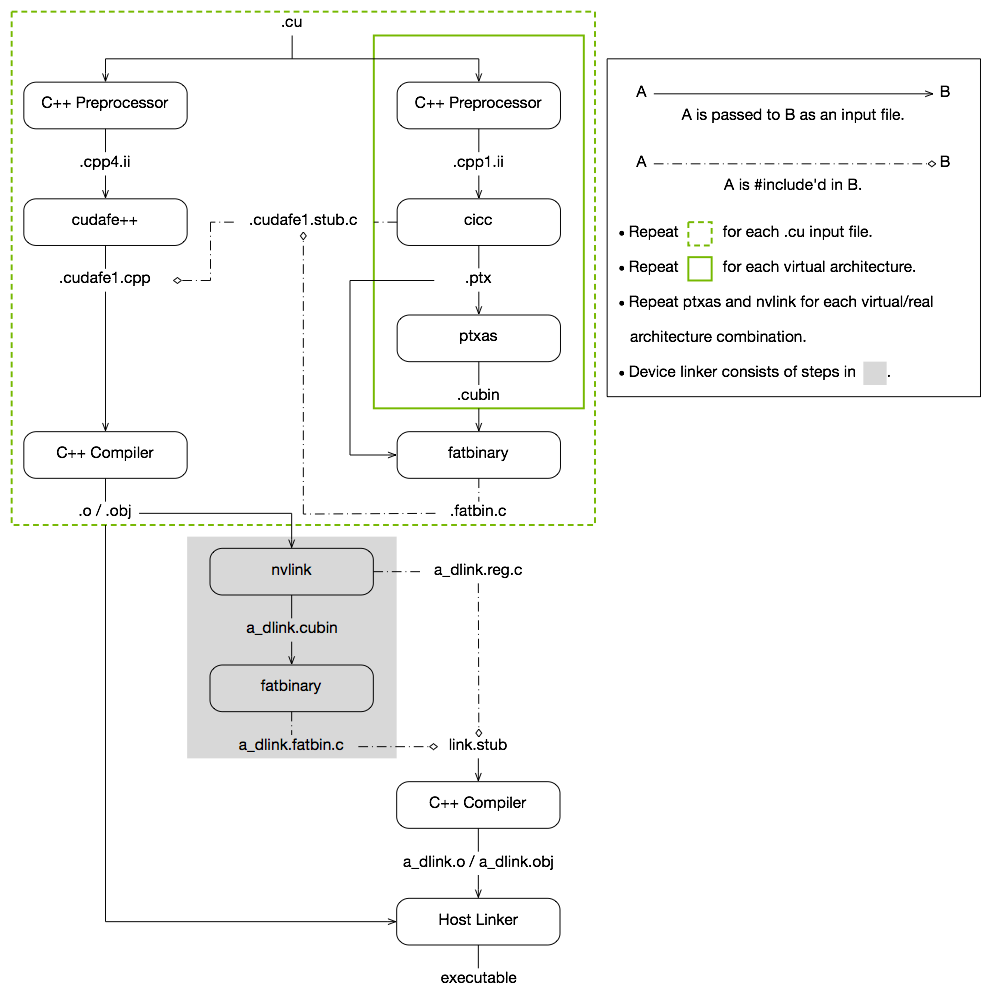
从 CUDA 源代码到可执行文件的完整编译流程
虚拟架构 vs 真实架构
在 CUDA 编译中,会接触到两种架构概念:
虚拟架构(PTX)
- 是什么:PTX 是一种虚拟的、与硬件无关的中间指令集,可以理解为”GPU 的汇编语言伪代码”。
- 干什么用:作为编译的中间产物,屏蔽不同 GPU 硬件的差异。一份 PTX 代码可以通过 JIT 编译运行在任何支持该 PTX 版本的 GPU 上。
- 命名格式:
ptxaa,如ptx70表示 PTX ISA 7.0 版本。
真实架构(SASS)
- 是什么:SASS 是 NVIDIA GPU 的真实机器指令集,直接对应具体 GPU 硬件架构(如 Ampere、Hopper)。
- 干什么用:GPU 真正执行的指令。每种 GPU 架构有自己的 SASS 指令集,不同架构之间不兼容。
- 命名格式:
sm_xx,如sm_80表示 Ampere 架构,sm_90表示 Hopper 架构。
两者关系
1
2
3
4
5
6
7
8
9
源代码 (.cu)
↓
编译
↓
虚拟架构 (PTX) ←─ 一次编译,多处运行
↓
JIT 编译(运行时)
↓
真实架构 (SASS) ←─ 针对具体 GPU 硬件优化
计算能力与 GPU 架构
什么是计算能力(Compute Capability)
计算能力是 NVIDIA GPU 的架构版本号,格式为 major.minor,例如:
| GPU 架构 | 计算能力 | 代表产品 |
|---|---|---|
| Kepler | 3.0-3.7 | GTX 700 系列 |
| Pascal | 6.0-6.2 | GTX 1000 系列,Tesla P100 |
| Volta | 7.0 | Tesla V100 |
| Turing | 7.5 | RTX 2000 系列 |
| Ampere | 8.0-8.9 | RTX 3000 系列,A100 |
| Hopper | 9.0 | H100 |
计算能力的作用
- 决定硬件特性:不同计算能力支持不同的特性(如 Tensor Core、Ray Tracing Core)
- 影响编译选项:编译时需指定
-arch=sm_xx来匹配目标 GPU - 限制资源使用:每个计算能力对寄存器数量、共享内存大小等有限制
编译时如何选择
1
2
3
4
5
6
7
8
# 只针对特定架构优化(性能最好,但兼容性差)
nvcc -arch=sm_80 -code=sm_80 hello.cu -o hello
# 生成 PTX 保证向前兼容(兼容性好,但首次运行慢)
nvcc -arch=sm_80 -code=compute_80 hello.cu -o hello
# 混合方式:同时生成 SASS 和 PTX(推荐)
nvcc -arch=sm_80 -code=sm_80,compute_80 hello.cu -o hello
查看自己 GPU 的计算能力
1
2
3
4
# 使用 deviceQuery 工具
/usr/local/cuda/samples/1_Utilities/deviceQuery/deviceQuery
# 或在线查询:https://developer.nvidia.com/cuda-gpus
PTX 的设计目的
PTX(Parallel Thread Execution) 是一种虚拟的 GPU 指令集架构,它的设计目的可以用一个通俗的比喻来理解:
想象你要写一本编程教程,但不知道读者会使用什么型号的电脑。于是你选择用一种”伪代码”来写,这种伪代码可以被翻译成任何型号的电脑都能理解的指令。PTX 就是这个”伪代码”。
为什么需要 PTX?
向前兼容:PTX 作为中间表示,使得同一份 CUDA 程序可以在不同代际的 GPU 上运行。NVIDIA 驱动程序中的 JIT(Just-In-Time)编译器会在程序运行时将 PTX 编译为当前 GPU 架构的原生 SASS 指令。
向后兼容:即使未来的 GPU 架构发生变化,只要支持 PTX,旧的 CUDA 程序仍然可以运行。
抽象硬件细节:开发者无需为每种 GPU 架构单独编译,只需指定目标计算能力(如
-arch=sm_80),nvcc 会自动生成对应的 PTX 和 SASS。
JIT 编译

JIT 编译在运行时将 PTX 转换为特定 GPU 架构的 SASS 指令
编译选项详解
| 选项 | 说明 |
|---|---|
-arch=sm_xx | 指定目标 GPU 架构(如 sm_80 表示 Ampere) |
-code=sm_xx | 生成特定架构的可执行代码 |
-ptx | 只编译到 PTX 中间代码 |
-cubin | 生成 CUDA 二进制文件(.cubin) |
-fatbin | 生成包含多种架构的胖二进制文件 |
示例:生成多架构胖二进制
1
2
# 为多种 GPU 架构生成代码
nvcc -arch=sm_80 -code=sm_80,sm_86,sm_90 hello.cu -o hello
这样生成的可执行文件可以在不同代际的 GPU 上运行。
参考链接
本文由作者按照 CC BY 4.0 进行授权